HMM模型
• 隐马尔科夫模型(Hidden Markov Model, HMM)是统计模型,它用来描述含有隐含参数的马尔科夫过程。用数学来表示为
maxP(h|w)=maxP(〖h_1 h_2…h_n |w〗_1 w_2…w_n)
• 对句子分词为例,其中,w=w_1 w_2…w_n为输入的句子,n为句子长度,w_i为句子中的每个字,h=h_1 h_2…h_n为输出的标签(B\E\M\S)。
比如有三个骰子,有6个面D6、4个面D4、8个面的D8,每个面的概率一样。开始掷骰子,先从三个骰子中随机选一个,然后掷骰子。
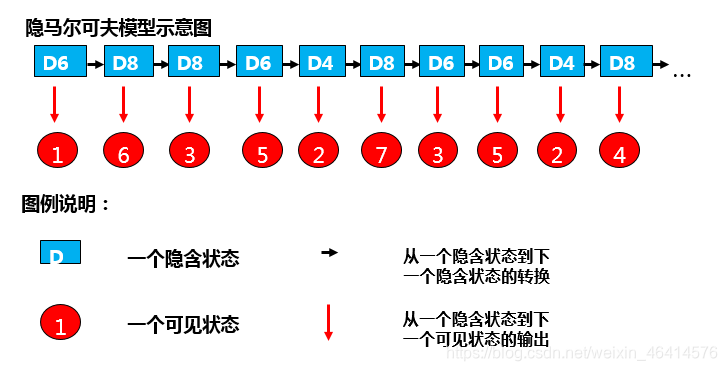
比如掷骰子10次,得到10个有序的数字(是一个可以看到的状态序列,称之为可见状态列)。从状态列中可以得知数字是从哪个骰子摇出来的,这个骰子的不可见的、只能通过推算得到的叫做隐含的状态列。
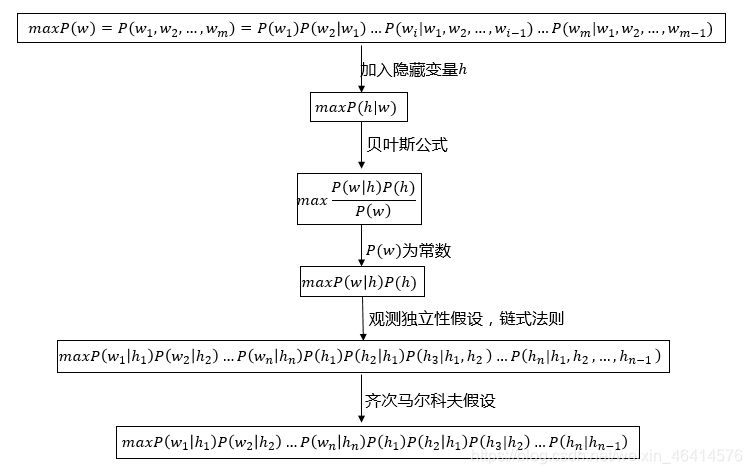
• 观测独立性假设:每个字仅仅与当前字有关。
• 转移概率:一个隐藏状态到下一个隐藏状态的概率;
• 发射概率:隐藏状态到观测状态的芥蓝菜;
• 通过设置P(h_k |h_(k-1))=0,可以排除类似BBB、EM等不合理的组合。
• 在HMM中,求解maxP(w│h)P(h)的常用方法是Viterbi算法。
条件随机场
• 设X=(X_1,X_2,…,X_n)和Y=(Y_1,Y_2,…,Y_m)是联合随机变量,若Y构成一个无向图G=(V,E)表示的马尔科夫模型,则其条件概率P(Y|X)称为条件随机场(Conditional Random Field, CRF)。
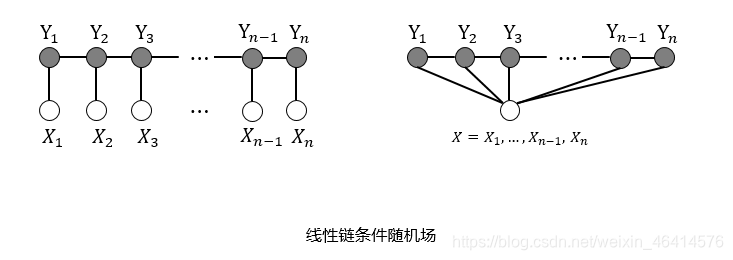
• 完整的线性链CRF表示为:
P(y│x)=1/(Z(x)) exp(∑_(i,k)▒λ_k t_k (y_(i-1),y_i,i)+∑_(i,l)▒μ_l s_l (y_i,X,i))
• 其中,Z(x)=∑_y▒〖exp(∑_(i,k)▒λ_k t_k (y_(i-1),y_i,i)+∑_(i,l)▒μ_l s_l (y_i,X,i))〗为规范化因子,t_k (y_(i-1),y_i,i)和s_l (y_i,X,i)为转移函数和状态函数,λ_k和μ_l为转移函数和状态函数对应的权值。
• 将上式简化为:
P(y│x)=1/(Z(x)) exp(∑_j▒〖∑_i▒w_j f_j 〗 (y_(i-1),y_i,x,i))
• 其中,Z(x)=∑_y▒〖exp(∑_j▒〖∑_i▒w_j f_j 〗(y_(i-1),y_i,x,i)" " 〗,f_j (y_(i-1),y_i,x,i)为t_k (y_(i-1),y_i,i)和s_l (y_i,X,i)的统一符号表示。
RNN
• 不同于传统的机器翻译模型仅仅考虑有限的前缀词汇信息作为语义模型的条件项,递归神经网络(RNN)有能力将语料集中的全部前序词汇纳入模型的考虑范围。
如果预测句子的下一个单词是什么,一般需要当前单词和前一个单词。就是说RNN的隐含层节点之间有连接。RNN的隐藏层也是全连接的。RNN的主要作用就是将先前的信息运用到当前,有一定的记忆功能。但会出现一个长期依赖的问题。
LSTM
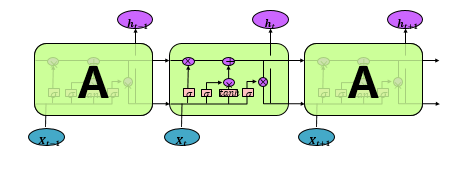
• 长短期记忆网络(Long Short Term Memory,LSTM):一种特殊的 RNN 类型,可以学习长期依赖信息。
• LSTM 通过刻意的设计来避免长期依赖问题。记忆长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。LSTM是一种拥有三个“门”结构的特殊网络结构。
• LSTM 靠一些“门”的结构让信息有选择性地影响RNN中每个时刻的状态。所谓“门”的结构就是一个使用sigmod神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”结构。之所以该结构叫做门是因为使用sigmod作为激活函数的全连接神经网络层会输出一个0到1之间的值,描述当前输入有多少信息量可以通过这个结构,于是这个结构的功能就类似于一扇门,当门打开时(sigmod输出为1时),全部信息都可以通过;当门关上时(sigmod输出为0),任何信息都无法通过。
GRU
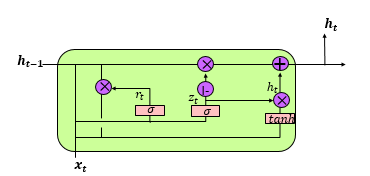
• GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门和输入门用更新门来替代。 把cell state和隐状态h_t进行合并,在计算当前时刻新信息的方法和LSTM有所不同。
• 重置门:rt
• 更新门:Zt
• 候选记忆单元:ht
• 当前时刻:ht
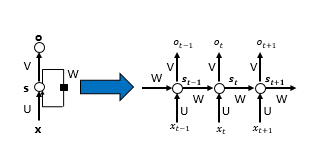
双向RNN:BiRNN
• 在经典的循环神经网络中,状态的传输是从前往后单向的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。这时就需要双向RNN(BiRNN)来解决这类问题。例如预测一个语句中缺失的单词不仅需要根据前文来判断,也需要根据后面的内容,这时双向RNN就可以发挥它的作用。双向RNN是由两个RNN上下叠加在一起组成的。输出由这两个RNN的状态共同决定。