
分词的定义
• 中文分词(Chinese Word Segmentation) :指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
• 例如:一九九八年/中国/实现/进出口/总值/达/一千零九十八点二亿/美元
• 在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
规则分词
• 规则分词:是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句中的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。按照匹配切分的方式,主要有:
• 正向最大匹配法(Maximum Match Method, MM法)
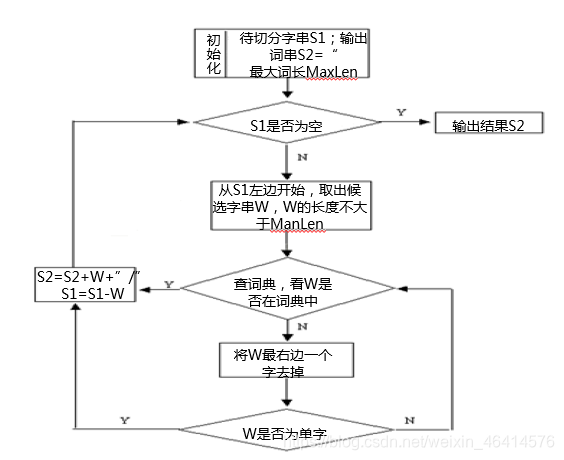
o 基本思想:假定分词词典中最长词有i个汉字字符,则用被处理文档的当前字符串中的前i个字作为匹配字段,查找字典。若字典中存在这样一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典找不到这样的词一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理。如此进行下去,直到切分出一个词或剩余字串的长度为0为止。
o 举例:“南京市长江大桥”切分为“南京市长\江\大桥”。
• 逆向最大匹配法(Reverse Maximum Match Method, RMM法)
o 与MM对比:由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精度。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
o 举例:“南京市长江大桥”切分为“南京市\长江大桥”,当然如此切分并不代表完全正确,可能有个叫“江大桥”的“南京市长”也不是没有可能。
• 双向最大匹配法(Bi-directction Match Method, MM法)
o 基本思想:将MM与RMM得到的结果相比较,按照最大匹配原则,选取次数切分最少的作为结果。
o 据SunM.S.和Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,MM与RMM的结果完全重合且正确;9.0%左右的句子两种切分方法不同,但其中必有一个是正确的;只有1.0%不到的句子,使用MM与RMM的切分虽重合但是错的或者切分不同但都是错的。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因。
• 特点:简单高效,词典维护困难。网络新词层出不穷,词典很难覆盖到所有词。
统计分词
• 主要思想:将分词作为字在字串中的序列标注任务来实现的。每个字在构造一个特定的词语时都占据着一个确定的构词位置,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。
四个标记:B=词首 M=词中 E=词尾 S=单独成词
两个标记:B=词首 I=非词首
输入: 中华民族是不可战胜的 中华民族是不可战胜的
标记: B M M E S B E B E S B I I I B B I B I B
输出: 中华民族/是/不可/战胜/的
• 步骤:
• 建立统计语言模型。
o 隐状态:字序列是观察序列,求隐藏的状态序列(HMM)。
o 类别标签:每个字的上下文构成特征,求当前字的词位类别(最大熵模型)。
• 对句子进行单词划分,然后对结果进行概率计算,获得概率最大的分词方式。如隐马尔科夫(HMM)、条件随机场(CRF)等。
深度学习分词
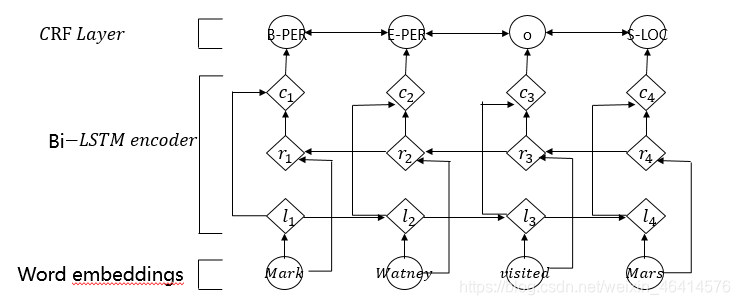
• 使用word2vec对语料的词进行嵌入,得到词嵌入后,用词嵌入特征输入给双向LSTM, 对输出的隐层加一个线性层,然后加一个CRF得到最终实现的模型。
混合分词
• 在实际工程应用中,多是基于一种分词算法,然后用其他分词算法加以辅助。最常用的是先基于词典的方式分词,然后再用统计分词方式进行辅助。